

Aprendizado de Máquina com Scikit-Learn
O aprendizado de máquina transformou a maneira como interpretamos dados, fornecendo insights profundos e permitindo previsões precisas em diversos domínios. Central para essa revolução está a biblioteca Scikit-Learn, uma ferramenta poderosa e acessível para implementar algoritmos de aprendizado de máquina em Python. Neste artigo, exploraremos os fundamentos dos algoritmos de aprendizado de máquina e demonstraremos um exemplo prático usando o Scikit-Learn, solidificando o entendimento teórico com aplicação prática.

Introdução aos Algoritmos de Aprendizado de Máquina
Os algoritmos de aprendizado de máquina podem ser amplamente categorizados em supervisionados, não supervisionados, e semi-supervisionados, cada um adequado para diferentes tipos de problemas de dados. Os algoritmos supervisionados são usados quando os dados vêm com labels indicando a resposta correta, enquanto os algoritmos não supervisionados exploram dados sem labels para encontrar padrões ou agrupamentos. Algoritmos semi-supervisionados, por sua vez, trabalham com uma mistura de dados rotulados e não rotulados.
Exemplo Prático: Classificação com Scikit-Learn
Para ilustrar o uso do Scikit-Learn, vamos implementar um modelo de classificação, um dos tipos mais comuns de algoritmos supervisionados.
Para isso vamos usar um exemplo prático, e muito comum, para a interpretação de modelos de classificação: Vamos prever se uma planta Iris é da espécie Setosa, Versicolour ou Virginica, com base em medidas como o comprimento e a largura das sépalas e pétalas.

Você consegue testar o código nesse notebook e fazer modificações a vontade 🔥
Passo 1: Importar as Bibliotecas Necessárias
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
Passo 2: Carregar e Preparar os Dados
O Scikit-Learn vem com um conjunto de dados Iris embutido, que podemos usar para treinar nosso modelo.
# Carregar o conjunto de dados
iris = load_iris(as_frame=True)
X = iris.data[["sepal length (cm)", "sepal width (cm)"]]
y = iris.target
Aqui, o conjunto de dados Iris é carregado com a função load_iris, especificando as_frame=True para obter os dados como um DataFrame do Pandas. O código seleciona apenas as características de comprimento e largura da sépala ("sepal length (cm)" e "sepal width (cm)") para X, e a variável alvo y é definida como a espécie da Iris.
Se quiser saber mais sobre o Pandas dá uma olhadinha nesse conteúdo abaixo:
 Rocketseat
Rocketseat
Passo 3: Divisão dos Dados
# Dividir os dados em conjuntos de treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Os dados são divididos em conjuntos de treinamento e teste usando train_test_split, com a estratificação baseada na variável alvo y para garantir uma distribuição equitativa das classes nos conjuntos de treino e teste.
Passo 4: Construção e Configuração do Pipeline
clf = Pipeline(
steps=[("scaler", StandardScaler()), ("knn", KNeighborsClassifier(n_neighbors=11))]
)
Um pipeline é criado com StandardScaler para normalização dos dados e KNeighborsClassifier com n_neighbors=11 para a classificação. O uso do pipeline simplifica o processo de transformação e aplicação do modelo.
Passo 4: Visualização das Fronteiras de Decisão
Vamos usar o algoritmo K-Nearest Neighbors (KNN) para classificar as espécies da Iris e no final vamos plotar o gráfico usando o pyplot a biblioteca matplotlib
for ax, weights in zip(axs, ("uniform", "distance")):
clf.set_params(knn__weights=weights).fit(X_train, y_train)
disp = DecisionBoundaryDisplay.from_estimator(
clf,
X_test,
response_method="predict",
plot_method="pcolormesh",
xlabel=iris.feature_names[0],
ylabel=iris.feature_names[1],
shading="auto",
alpha=0.5,
ax=ax,
)
scatter = disp.ax_.scatter(X.iloc[:, 0], X.iloc[:, 1], c=y, edgecolors="k")
disp.ax_.legend(
scatter.legend_elements()[0],
iris.target_names,
loc="lower left",
title="Classes",
)
_ = disp.ax_.set_title(
f"3-Class classification\\n(k={clf[-1].n_neighbors}, weights={weights!r})"
)
plt.show()
Mas, antes de rodar o código vamos entender ele parte a parte:
_, axs = plt.subplots(ncols=2, figsize=(12, 5))
for ax, weights in zip(axs, ("uniform", "distance")):
clf.set_params(knn__weights=weights).fit(X_train, y_train)
...
plt.show()
Aqui, duas visualizações são geradas em subplots, cada uma correspondendo a um tipo de ponderação diferente para o KNN ("uniform" e "distance"). O método set_params é usado para configurar dinamicamente a ponderação do KNN no pipeline antes de ajustar o modelo com os dados de treinamento.
disp = DecisionBoundaryDisplay.from_estimator(
clf,
X_test,
response_method="predict",
plot_method="pcolormesh",
xlabel=iris.feature_names[0],
ylabel=iris.feature_names[1],
shading="auto",
alpha=0.5,
ax=ax,
)
Essa seção do código utiliza DecisionBoundaryDisplay.from_estimator para desenhar as fronteiras de decisão do modelo no espaço das duas características selecionadas. A função scatter é usada para sobrepor os pontos de dados, com cores representando as diferentes classes.
Agora, vamos para a visualização da plotagem:
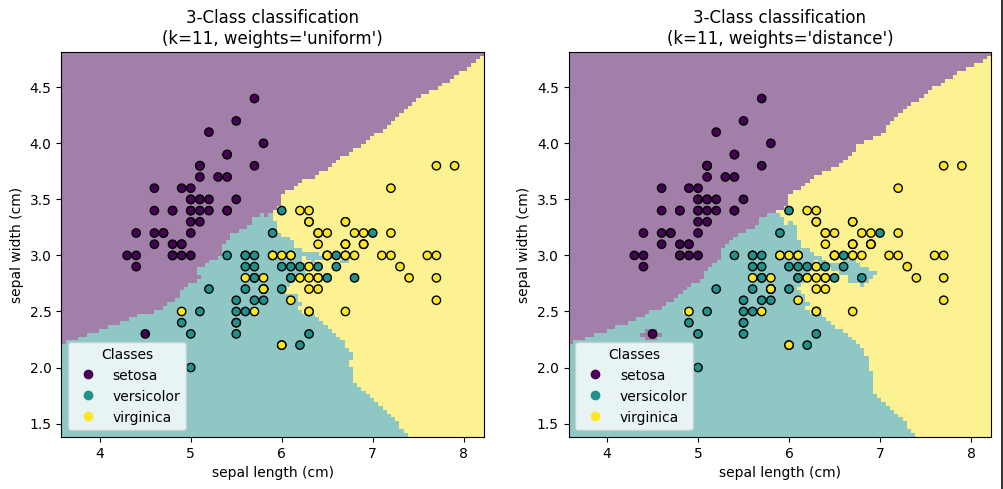
Que da hora, não?
Utilizando o conjunto de dados Iris e a implementação de um modelo de classificação K-Nearest Neighbors (KNN) com a biblioteca Scikit-Learn, podemos observar a potência e flexibilidade que essa ferramenta oferece aos cientistas de dados e pesquisadores. A capacidade de visualizar as fronteiras de decisão para diferentes tipos de ponderação do KNN não apenas concretiza o entendimento dos conceitos teóricos por trás desses algoritmos, mas também enfatiza a importância da análise exploratória na modelagem de aprendizado de máquina. Ao ajustar os parâmetros do modelo e examinar visualmente como essas mudanças afetam a classificação, os profissionais podem tomar decisões mais informadas sobre como melhorar seus modelos para alcançar resultados mais precisos e confiáveis.