

Regressão Linear Simples: Inteligência Artificial (IA) com Python
A Regressão Linear Simples é uma técnica estatística fundamental no campo da Inteligência Artificial (IA) e do aprendizado de máquina, servindo como pedra angular para prever relações entre variáveis. Este artigo explora a implementação dessa técnica utilizando Python, com foco na biblioteca scikit-learn, uma das mais renomadas ferramentas para aprendizado de máquina.
Antes de prosseguir com a leitura do Artigo é necessário um conhecimento sobre Analise de Regressão, então sugiro a leitura do conteúdo a seguir:
 Paulo Clemente
Paulo Clemente
Introdução à Regressão Linear Simples
No cerne da regressão linear simples está a modelagem da relação entre duas variáveis quantitativas: uma variável independente (X) e uma variável dependente (Y). O objetivo é desenhar uma linha reta que melhor descreva essa relação, habilitando previsões precisas de Y baseadas em novos valores de X.
Configurando o Ambiente de Desenvolvimento
O primeiro passo é preparar o ambiente de desenvolvimento com as bibliotecas necessárias, incluindo scikit-learn para modelagem, numpy para manipulação de arrays, e matplotlib para visualização. Estas podem ser instaladas via pip, o gerenciador de pacotes do Python.
Implementação Detalhada
A seguir, um passo a passo para a implementação de uma regressão linear simples em Python:
Passo 1: Importação das Bibliotecas para desenvolver
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
Essas importações preparam o “terreno” para manipulação de dados, visualização e modelagem estatística.
Passo 2: Preparação dos Dados
Utilizamos numpy para criar um conjunto de dados sintético, representando nossa variável independente (X) e dependente (y). A seguir, dividimos os dados em conjuntos de treino e teste, uma prática essencial para validar a performance do modelo.
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
y = np.array([2, 4, 6, 8, 10, 12, 14, 16, 18, 20])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
- Criamos arrays
Xeyusandonumpy, ondeXé a variável independente eya dependente. train_test_splitdivideXeyem conjuntos de treino e teste, essencial para validar o modelo sem viés.
Passo 3: Criação e Treinamento do Modelo da
Instanciamos e treinamos o modelo de regressão linear utilizando os dados de treino, afim de ajustar a linha que melhor representa a relação entre X e Y.
modelo = LinearRegression()
modelo.fit(X_train, y_train)
- Instanciamos
LinearRegression, que é nosso modelo de regressão linear. fittreina o modelo nos dados de treino (X_train,y_train), ajustando a melhor linha que descreve a relação entreXey.
Passo 4: Fazendo Previsões
Com o modelo treinado, realizamos previsões sobre o conjunto de teste para avaliar como o modelo generaliza para novos dados.
y_pred = modelo.predict(X_test)
predicté usado para fazer previsões sobre o conjunto de teste (X_test), baseado no modelo treinado.
Passo 5: Avaliação do Modelo
A eficácia do modelo é avaliada por métricas como o R², que quantifica o quanto da variação na variável dependente é explicada pelo modelo.
r2_score = modelo.score(X_test, y_test)
print(f"R²: {r2_score}")
scoreavalia o modelo com base no conjunto de teste, fornecendo o R², que mede quão bem as previsões correspondem aos dados reais.
Passo 6: Visualização dos Resultados
Por fim, visualizamos os dados reais e a linha de regressão ajustada para uma compreensão intuitiva da performance do modelo.
plt.scatter(X, y, color='blue')
plt.plot(X, modelo.predict(X), color='red')
plt.title('Regressão Linear Simples')
plt.xlabel('Variável Independente')
plt.ylabel('Variável Dependente')
plt.show()
E no final teremos esse gráfico:
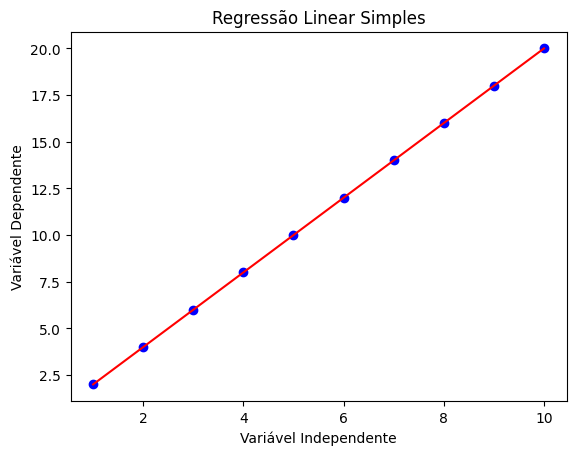
Intuitivamente, percebemos que o gráfico mostra que a relação entre as variáveis independente (X) e dependente (Y) é diretamente proporcional e linear, indicando que conforme X aumenta, Y também aumenta de forma constante.
A linha de regressão (em vermelho) passa muito próxima ou diretamente por todos os pontos (azuis), sugerindo que o modelo tem um alto grau de precisão. Isso é corroborado pelo fato de os pontos de dados estarem alinhados, indicando pouca ou nenhuma variação residual em torno da linha de regressão, o que é ideal numa regressão linear simples.
Você pode ter acesso e também testar o código do passo a passo visto nesse artigo neste Notebook.
Este artigo demonstrou a implementação de uma regressão linear simples em Python, utilizando a biblioteca scikit-learn. Esse processo ilustra não apenas a simplicidade da modelagem estatística com Python, mas também a potência das bibliotecas disponíveis para análise de dados e aprendizado de máquina. Compreender e aplicar a regressão linear simples é um passo crucial para qualquer profissional que deseja avançar no campo da IA, servindo como base para técnicas mais complexas e modelos preditivos sofisticados.


